


This article is the third in a series on the Data & AI Product approach and how to craft impactful Data & AI Products. The first article explained the main causes of failure in Data & AI Products today, while the second one focused on the heavy task of defining what is a Data & AI Product. In this article, we deep dive into the reasons why traditional Agile and Product Management approaches fail with Data & AI, and explore how Lean can be at the heart of a new approach for delivering value through Data & AI.
Happy reading, and we welcome your feedback to share your own experiences!
The story repeats itself with clockwork precision. A data team announces they're "going Agile."

Three months later, they're drowning in technical debt, missing deadlines, and questioning every principle they tried to adopt. Data & AI hold the promise to transform industries, yet many teams find themselves stuck, spinning their wheels, and failing to deliver at the pace expected.
Why? It's not for lack of trying. Many of these teams are using Agile and Product Management techniques—the same strategies that drive success in software development. So why aren’t they working here?
The answer lies in the fact that blindly applying traditional Agile and Product Management approaches is not enough to face the challenges of Data & AI.
Let’s break down why.
A Square Peg in a Round Hole
In software development, Agile thrives on breaking work into small, iterative tasks, allowing teams to deliver value in short, frequent cycles by continuously shipping functional code.
But Data & AI don’t fit this mold. The very nature of data science and machine learning work brings a high degree of unpredictability. Accurately forecasting how long it will take to train a model or clean datasets is notoriously difficult.
Ask a data scientist to write user stories for machine learning tasks, and you’re likely to get something like "Model V1" or "Model V2"—a far cry from the structured, iterative work that is expected.

This misalignment causes frustration among Product Managers and Software Engineers, who may start seeing Data & AI teams as "different" or even "lazy."
As a result, the Data Death Cycle continues—teams lose faith in Agile, revert to older methods, and fail to deliver high-impact data products efficiently.
What We’ve Forgotten: The Core of Agile and Product Management
The problem isn’t with Agile or Product Management themselves. It's how they are applied. Too many teams and organizations treat these methodologies as rigid frameworks.
They follow the rituals—holding meetings, running ceremonies, and delivering according to the “rules”—but lose sight of the core principles behind them.
Agile was never about a checklist of activities. It was designed to foster collaboration, empower teams, and deliver value quickly. The same goes for Product Management. Unfortunately, this essence is often forgotten.
As a result, many Data & AI teams are suffering from what can only be called "Agile fatigue."

Why Traditional Agile Fails Data Teams
Three core issues explain why Agile struggles in the context of Data & AI:
Uncertainty: Data work involves far more unknowns than traditional software development. A data scientist can’t predict how long it will take to reach 90% model accuracy.
Value Demonstration: While software engineers can show working features early, data scientists often can’t demonstrate progress until deep into a project.
Different Backgrounds: Data professionals often come from academic or research backgrounds, where the scientific method is valued over iterative development.
As it turns out, those struggles are rooted in the Data & AI history. Let’s explore it briefly.
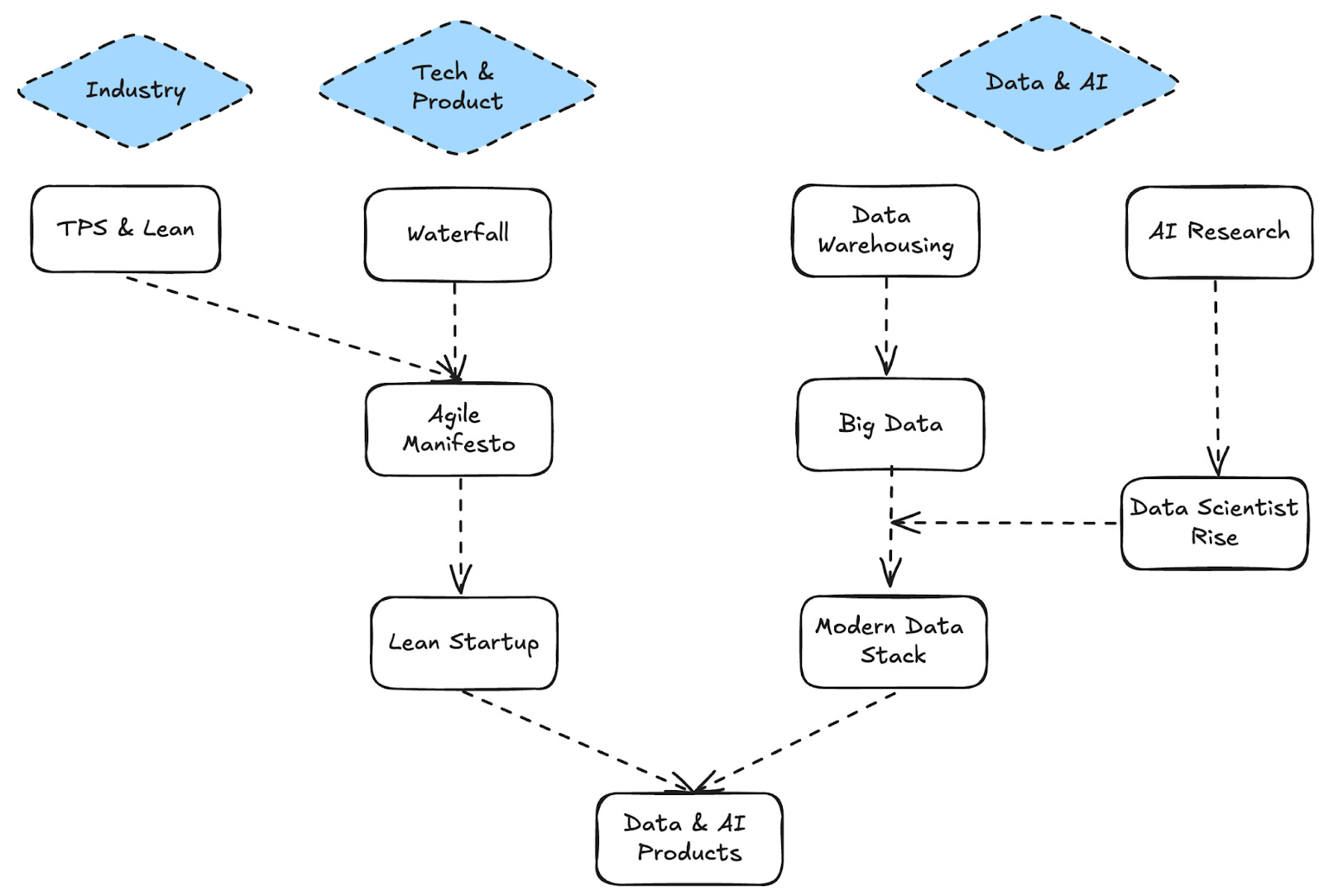
Revisiting the Data & AI History
The Big Data Bubble (2004-2015)
When Google unveiled its groundbreaking papers on the Google File System and MapReduce, it didn’t just share technology—it revealed how a tech giant handled data at scale.
Companies rushed to replicate this success. They invested in huge Hadoop clusters, hired specialized engineers, and envisioned data-driven transformations.
But there was a catch.
The complexity of their tools demanded specialized expertise. Data Engineers became the gatekeepers of an increasingly complex infrastructure.
Result: While software teams were embracing Agile and iterative development, Big Data teams remained siloed. The complexity of their systems made quick iterations impossible, leaving them focused primarily on maintenance.
The Data Science Gold Rush (2012-2019)

Harvard Business Review's famous 2012 article calling Data Scientist "the sexiest job of the 21st century" triggered a gold rush. Companies built data science teams faster than they could spell "neural network."
Data scientists, who according to the article "make discoveries while swimming in data," clashed with Agile’s emphasis on iterative, predictable improvement.
Result: Data scientists worked in separate "data labs," distant from product development. Agile frameworks buckled under the weight of discovery-driven work. You can’t exactly write a user story for “find patterns we don’t know exist yet.”
The Modern Data Stack Era (2020-Present): Simplicity Meets Chaos

Then came the Modern Data Stack. Tools became simpler, and data engineering shifted from building complex systems to connecting modular components like LEGO bricks.
With the barriers to entry lowered, analysts moved closer to business teams, and data democratization took hold.
Yet, despite these advancements, teams still struggle to deliver value consistently. Why?
While the tools have simplified, the fundamental mindset challenges remain. Data teams still struggle with traditional two-week sprints. Product Managers still see data work as opaque and unpredictable.
The DataOps Revolution (2015-Present): Lean Strikes Back
In parallel to these struggles, the DataOps movement emerged, promising to bring Lean principles to data pipelines in much the same way DevOps did for software development.
The premise was attractive:
Apply Lean manufacturing principles to data pipelines
Automate testing and deployment
Enable continuous delivery of data products
Reduce errors through standardization
But while DataOps improved operational efficiency, it’s still narrowed down to operational data management. The fundamental issue remains present: creating valuable insights and products. Clean pipelines don’t guarantee useful discoveries.
The Lean Mindset: An Overlooked Solution
All is not lost, though.
When Data & AI teams adopt a product mindset, they stop asking, “How do we force Agile into this?” and start asking a better question: “How do we deliver real value, fast?” Some adapt Scrum to their needs, while others discard Agile but maintain a focus on delivering value, freeing themselves from traditional project mindsets.

What can we learn from this? That it’s time to revisit the origins of Agile and Product Management—Lean Thinking.
Originating from manufacturing, Lean Thinking focuses on eliminating waste and continuously improving processes. Toyota’s revolutionary principles like Genchi Genbutsu (going to the source of the facts) and Kaizen (continuous improvement) helped fuel decades of growth and heavily influenced the Agile movement.
Lean isn't just for production lines—it’s about delivering value efficiently. Lean Thinking birthed DevOps in the software world, and it could transform Data & AI as well.
A Call for a New Approach
As companies face growing pressure to demonstrate ROI from data investments, building effective data product development practices becomes critical.
The solution lies in embracing a product mindset grounded in Lean Thinking. Copying Agile and Product Management frameworks won’t work.
It’s about acknowledging the unique nature of data work while maintaining Lean’s focus on learning, iterating, and delivering value.
This requires:
Accepting that uncertainty is the only certainty
Focusing on solving problems, not following methodologies
Measuring progress in new ways
Abandoning ritual for ritual’s sake
We need a new synthesis—a blend of Lean principles and the realities of Data & AI work. The future of Data Product development won’t look exactly like software Agile. And that’s okay.
Lean Thinking offers a way to move beyond rigid, inefficient cycles and towards delivering impactful Data & AI products. It encourages collaboration across Data, Product, and Engineering teams and pushes for real, measurable value.
The key question isn't "How do we make data teams more Agile?" but "How do we help data teams deliver value consistently while embracing their unique workflows?"
The answer to that could reshape the future of data product development.
This what we’re going to explore and unveil in the upcoming articles.
What do you think? Have you witnessed failures with applying Agile to Data & AI? How have you faced this challenge?
Stay tuned for the next articles to learn how to escape the Data Death Cycle and Craft Impactful Data & AI Products! We will continue to talk a lot about Product Management and its application to Data & AI.
Agree overall. However, 'data and AI' seems to be generalising a lot here. Take the case of a BI team developing dashboards over a DWH. If the DWH is mature, is well modelled and has good data pipelines, and the BI team have worked with the DWH for some time and have developed other dashboards before, then there should be few unknowns in the dashboard development process. It should be able to be handled in an agile type fashion. In fact dashboards can benefit from some iteration because it is hard for users to know just what they want until they start to see something.
I actually think you could re=write your article substituting software development for data and AI development and get a similar reaction from many in the agile software community. I think you even say at one point “the problem isn’t with agile … it’s how it’s applied”.
Forgive me if I tell a story. I was working with a customer’s data team on getting some new complex dashboards built and discussed with the CTO/CDO the need to slice the work finer in order to generate faster feedback. Their software teams were familiar with Alistair Cockburn’s elephant carpaccio workshop and I had been thinking of a version of this for data teams. I was convinced you could not do the “pure” software dev version. Long story short we ended up doing the “pure” software dev version and the data team agreed this helped them and they could adapt the practices for their circumstances. I was convinced that agile software development techniques needed to be adapted for data engineering but was proved wrong.
Yes, they need to be adapted for data engineering and data and AI products but the underlying principles of agile actually work well.