
The Data Death Cycle
Why do so many Data Products and Initiatives never create the expected value?


This article is the first in a series on the Data & AI Product approach and how to craft impactful Data & AI Products. This first article aims to explain the main causes of failure in Data & AI Products today. Happy reading, and we welcome your feedback and any other causes of failure you have identified in your experiences.
No matter our role — whether we’re a Data expert, a Data leader, an Engineer, a Product Manager, a Marketer, a C-Level executive, or a CEO — we’ve all witnessed countless Data & AI initiatives that failed to deliver on their promises. Too often, these projects gather dust, never making it into users’ hands or generating the value we envisioned.

In our organizations or in past projects, we’ve all faced these familiar challenges:
Algorithms developed with care but never deployed to production
Proofs of Concept (POCs) that showed promise but fell short when it came time for real-world application
Technical prototypes brimming with potential, but lacking the commitment needed to bring them to life
Users clinging to old habits, unable to see the value in adopting something new…
Before the rise of Generative AI (GenAI), Gartner predicted that 85% of AI projects would fail to deliver the expected results due to biased data, flawed algorithms, or the complexities of team dynamics. While the advent of GenAI — bringing user-friendly interfaces and bridging the gap between technology and business — was expected to lower this rate, challenges persist. A recent Gartner study forecasts that by 2025, 30% of GenAI projects will still be abandoned after the proof-of-concept (PoC) stage. The reasons? Poor data quality, inadequate risk management, spiraling costs, and unclear business value.
These statistics reveal a stark truth: reducing the technological gap alone is not enough to ensure success in AI or GenAI projects. The risk of failure remains high, pointing to deeper systemic issues beyond just technology.
We seem trapped in a repeating pattern of mistakes — a vicious cycle we call the Data Death Cycle.

It’s easy to blame a single person, lack of expertise, or an immature technology stack for why Data & AI products fail to deliver value. While these might play a role, our experience reveals deeper, recurring patterns. We’ve identified five common traps that Data teams often fall into:
The Tech Trap
The Doing Trap
The Project Trap
The Silo Trap
The Performance-First Trap
Let’s break down each of these traps and explore why they derail so many Data & AI initiatives.
Trap #1: The Tech Trap
The Tech Trap snares Data teams when they start with technology rather than user needs. The conversation usually begins with questions like:
What problems could this technology solve?
How can we integrate this technology into our processes?
This approach is fraught with risk. It assumes that the technology’s capabilities are inherently valuable, leading to unverified assumptions about the user problems it might address. The danger is that deep into development, you may discover:
There’s no real user problem being solved.
The focus doesn’t align with current business priorities.
There are more urgent issues that require attention.
People are simply not interested.
Steve Jobs famously captured this pitfall at the 1997 Apple Worldwide Developers Conference (WWDC):
“You’ve got to start with the customer experience and work back toward the technology — not the other way around.”
When Jobs said this, Apple was struggling, and his return marked a shift toward a customer-centric philosophy. Jobs emphasized that Apple’s approach should be driven by the user experience, rather than starting with the technology and trying to find a use for it. This focus on user experience led to game-changing innovations like the iPhone and iPad — products that didn’t just showcase technology but solved real user problems.
Today, we see a similar pattern with the hype around GenAI. Too many companies rush to cram GenAI features into their products, often at the insistence of investors or stakeholders eager to ride the AI wave. The outcome? Flashy but hollow “GenAI features” that add little to no real value.
Consider a business app that integrates a GenAI chatbot to answer basic FAQs. A simple rule-based system or a well-structured FAQ page would have done the job just as well, if not better. These tech-centric decisions result in products that serve as tech demos rather than tools that improve user experience or solve meaningful problems.
Instead of chasing the latest tech fad, ask a more fundamental question:
What specific problem are we trying to solve, and is there a simpler, more direct solution?
A well-targeted, uncomplicated solution often delivers more value than a flashy, complex feature that no one truly needs.
Trap #2: The Doing Trap
When faced with a challenge, our minds often draw on past experiences, quickly surfacing similar scenarios — and with them, the solutions we previously used.
This reliance on experience or intuition can be a strength, allowing us to act swiftly in familiar situations. However, most situations aren’t carbon copies of the past; the context and people involved are often different.
")
The danger lies in jumping straight to a familiar solution, designing and delivering it, only to find that users point out unique nuances that render another approach more effective.
Alternatively, internal teams or users may push back against the proposed solution because they don’t see the intuitive reasoning or past experiences that led to its selection over their own ideas. This disconnect is often mistaken for a lack of data adoption, prompting efforts to convince stakeholders to accept an alternative approach rather than reevaluating the core issue.
This type of rapid, intuitive decision-making primarily engages the ventromedial prefrontal cortex — the brain region responsible for blending emotional insights and past experiences to drive quick choices. While essential in urgent, life-threatening scenarios (like fleeing from a fire when smoke is detected), this approach can fall short in addressing complex challenges that Data & AI are meant to solve.
These situations require a more balanced cognitive strategy, toggling between the ventromedial prefrontal cortex for intuitive judgments and the dorsolateral prefrontal cortex, which governs planning, logical reasoning, and analytical decision-making. This latter region is key for devising strategies that tackle intricate problems by considering multiple factors.
Take, for instance, a Data team tasked with improving lead scoring for a company swamped with customer leads. With their deep expertise in machine learning, the team leaps to an “obvious” solution: deploying a sophisticated AI model to predict lead conversion rates based on historical data. But they miss a critical insight — the sales department already has an effective, intuitive method: a simple “Last In, First Out” (LIFO) rule to prioritize recent leads, which tend to convert better. The real problem wasn’t the absence of a complex scoring algorithm; it was the difficulty of applying this intuitive rule within their existing workflow. By defaulting to their preconceived solution, the data team missed a chance to save the sales team an hour daily with a straightforward tweak in lead display.
The best solutions aren’t always the most advanced — they’re the ones that seamlessly evolve with current practices.
Trap#3: The Project Trap
When it comes to managing complex deliverables, the conventional wisdom is to adopt a “project” approach. This method involves breaking down goals into a series of tasks and deliverables, all neatly mapped out within a fixed budget and timeline. On the surface, this approach seems like a recipe for order and efficiency. However, it often collapses under the weight of real-world complexities that inevitably arise during execution.

In the dynamic environment of Data & AI Product development, unexpected changes are not the exception — they are the norm. Yet, traditional project management frameworks rarely account for this level of unpredictability. When confronted with unforeseen obstacles or shifts in priorities, teams are left at a crossroads: they can either stick rigidly to the original plan or make a series of ad-hoc adjustments.
Both choices come with significant risks. Sticking to the plan often means ignoring critical shifts in the landscape, while making isolated adjustments can lead to a fragmented approach where the overall objective is lost in the shuffle. Without pausing to reassess the overarching problem and the value the project is meant to deliver, teams risk creating disjointed solutions that fail to hit the mark.

Take, for example, a Data team tasked with developing a recommendation algorithm for an e-commerce platform. The team dives into the work, laser-focused on each task and confident in the plan. However, during the months they spend perfecting the algorithm, the broader strategy of the e-commerce company pivots. Instead of focusing on cross-selling products, the company decides to prioritize improving the landing page performance to increase overall conversion rates.
Caught up in the momentum of the original plan, the Data team remains oblivious to this strategic shift. They continue to invest time and resources into a recommendation algorithm that, while technically advanced, is no longer aligned with the company’s evolving priorities. The end result? A technically robust solution that is strategically irrelevant — an AI Product that no longer adds value to the business.
This scenario illustrates the core flaw of the “Project Trap”: the false sense of security provided by a rigid plan. When teams are too focused on delivering what was initially outlined, they often miss the opportunity to adapt to the changing needs of the organization. Instead of creating meaningful value, they end up with products that serve a purpose that has long since expired.
Effective Data & AI Product development is not just about delivering on time and within budget; it’s about continuously aligning with the organization’s evolving needs and strategic goals. Without this flexibility, even the most well-executed project can end up as wasted effort.
Trap #4: The Silo Trap
Data & AI initiatives are rarely the domain of a single team. Delivering real value requires collaboration across Engineering, Product, Sales, Marketing, Security, IT, and, crucially, the end-users. Yet, in a misguided attempt to streamline processes or manage complexity, these initiatives often fall into the “silo trap,” where work is done in isolation.
This fragmented approach creates several significant problems:
When one team encounters an unforeseen issue during the project and implements a solution independently, it can inadvertently make the solution unworkable for another team without their knowledge or input.
If one team’s timeline shifts unexpectedly, it often results in delays for other teams dependent on that schedule. With no clear communication, teams fail to adjust their plans, creating a ripple effect of setbacks.
The core issue is an underestimation of how critical communication is in delivering Data & AI initiatives. Conway’s Law captures this well:
“Organizations which design systems are constrained to produce designs which are copies of their own communication structures.”
Another illustration is the familiar communication silos in large organizations by Manu Cornet:
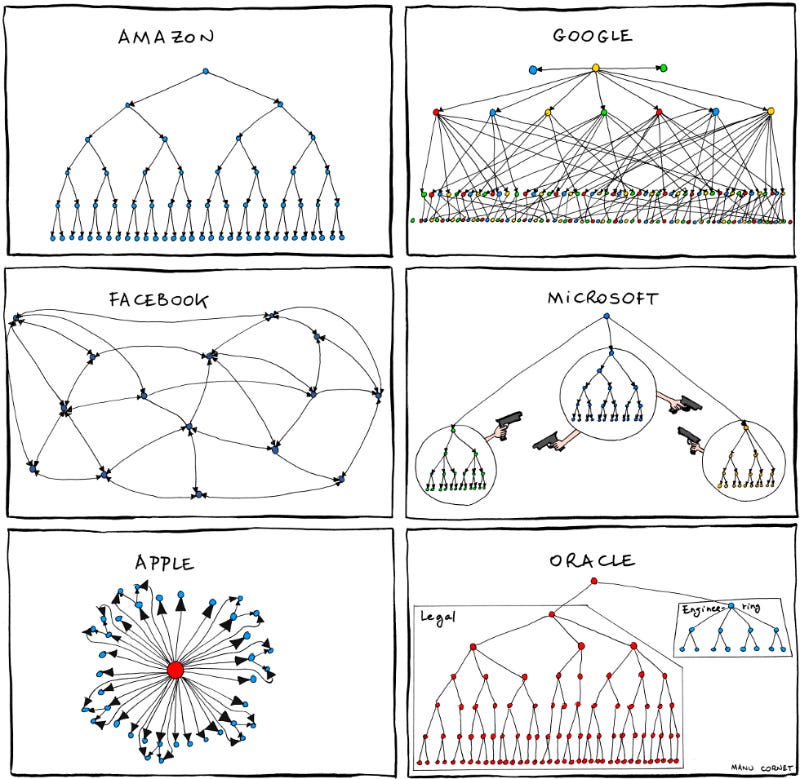
Let’s look at another example involving a recommendation engine for an e-commerce platform. The Data team develops a sophisticated model based on historical purchase data to predict customer preferences. However, they operate in isolation, without ongoing input from the Marketing team, who will use these recommendations to drive personalized campaigns. By the time the model is ready for launch, the Marketing team discovers that the outputs aren’t formatted for their needs, and worse, they don’t align with the latest campaign strategy. Meanwhile, the IT team is blindsided by the additional computational resources required to run the model in real-time, leading to unexpected system slowdowns.
The result? Extensive rework across multiple teams, delayed launches, and waning enthusiasm for the product — an all-too-common outcome of siloed development. Misaligned goals, incompatible outputs, and operational headaches arise, all of which could have been avoided with stronger cross-team communication and collaboration.
So, reflect on this in your current situation:
What does the communication structure look like in failed Data & AI initiatives?
Where are the communication gaps?
What changes can you experiment with to improve the flow of information and alignment across teams?
Trap #5: The Performance-First Trap
A widespread misconception about Data & AI initiatives is that their value is solely tied to technical performance. This misunderstanding often leads teams into what we call the “performance-first trap.” When there’s no clear, shared understanding of the desired value, teams risk focusing too narrowly on data metrics rather than the broader impact of the product.
When Data teams lead the initiative, they often prioritize the technical performance of the data deliverables:
For a data visualization tool, they may focus on ensuring that 100% of the data is accurate and up-to-date.
For an AI algorithm, they might zero in on maximizing model accuracy, sometimes without even defining a specific performance threshold.
While these metrics are undoubtedly important — especially in ensuring that a minimum threshold is met to create value — they don’t capture the full spectrum of what a Data & AI product should deliver.
Consider a scoring algorithm designed to detect a particular behavior. If the current method only identifies the behavior in one out of every two cases, an algorithm with 80% accuracy might be more than adequate for an initial rollout. Striving for 95% accuracy from the start could be unnecessary. The appropriate threshold depends heavily on the context and the specific problem being addressed.
Or take a computer vision algorithm that achieves 98% accuracy in object detection but has a 5-minute processing delay. While the accuracy is impressive, such a delay could make the solution impractical for real-time applications.
“Data performance” is undeniably crucial in determining the viability of a Data & AI initiative. However, if performance becomes the sole measure of value, it can lead to building a technically robust product that fails when deployed in real-world scenarios.
True value emerges when a product not only performs well in data terms but is also effectively used by the end user to achieve a meaningful outcome. Even the most accurate algorithm only delivers value when there is a tangible business opportunity and when it is seamlessly integrated into a user experience that works.
In product management, “value” isn’t just about technical performance — it’s about the tangible benefits the product delivers to users and customers, which ultimately translates into business success.
A common pattern: the Data Death Cycle
Across industries and company sizes, data teams repeatedly face the same frustrating pitfalls. An invisible barrier seems to stop them from achieving their full potential. We call this the Data Death Cycle — a recurring pattern of wasted effort, inspired by David J. Bland’s Product Death Cycle.
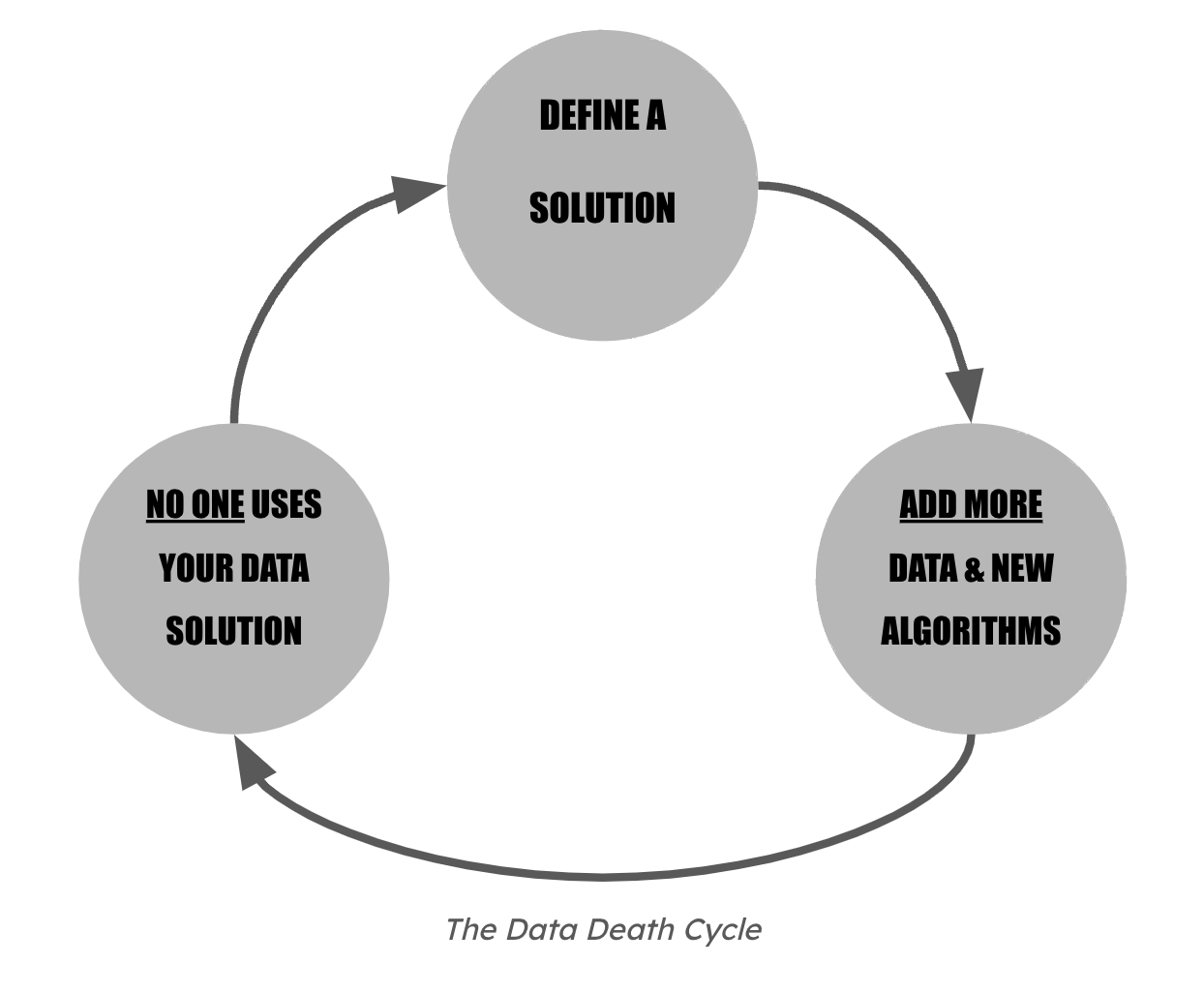
The cycle starts with a rush to define a new Data & AI solution. Eager to demonstrate their technical prowess, the Data team dives into brainstorming and designing without a deep understanding of the business needs or user pain points. Whether self-initiated or driven by stakeholder requests, the solution is often conceived in a vacuum, prioritizing technical sophistication over practical value.
Armed with a poorly defined solution, the Data team then pour resources into gathering data and building complex algorithms. The focus shifts to creating technically impressive models rather than developing something user-friendly and valuable. The result is often a convoluted solution that impresses in theory but is disconnected from real-world needs.
The final and most disheartening step in the Data Death Cycle is the realization that no one uses the solution. Despite the heavy investment, users find it too complex, misaligned with their needs, or redundant.
The Data team, disheartened, scrambles to iterate based on limited feedback, but the core problem — misalignment with user needs — remains unresolved. This leads to a cycle of minor adjustments that fail to address the fundamental issue.
Once caught in the Data Death Cycle, teams find it hard to escape. Much like the “waiting for the bus” syndrome, having already invested significant time and effort, teams feel compelled to continue, believing that success is just a few tweaks away. This reluctance to pivot only deepens the cycle of misalignment and wasted effort.
In the rush to build solutions, the underlying question is often overlooked: Are we even addressing the right problem? Without this foundational clarity, teams are doomed to repeat the same cycle, missing the real opportunity to create meaningful impact.
In the following articles, we will delve into ways to escape this Data Death Cycle.
What do you think? Do you see any other traps that cause Data & AI initiatives to fail in delivering the expected value?
Hint: We will talk a lot about Product Management and its application to Data & AI.
Wow! Perfectly summarized. From what I've observed so far, it all comes down to better communication between Data and Business teams. It’s crucial to properly scope the right problems at the start of a project and throughout its lifecycle by explaining the reasoning behind each request. For example, the business might want to add a feature, but it’s important to clarify: what question is this feature meant to answer?
For anything to change, someone at the top has to have the courage to reflect, envision the changes needed, and lead their implementation. Fighting status quo is a difficult battle that not many are willing to undertake.